

Eine XML-Sitemap und eine robots.txt-Datei gehören zu den wichtigsten technischen Grundlagen der Suchmaschinenoptimierung (SEO). Während die Sitemap Suchmaschinen wie Google einen Überblick über alle wichtigen URLs einer Website gibt, hilft die robots.txt-Datei dabei, das Crawlen bestimmter Inhalte zu steuern. Beide Tools gehen also Hand in Hand, wenn es darum geht, die Sichtbarkeit deiner Website in den Suchmaschinen besser zu kontrollieren. In diesem Artikel erfährst du alles, was du darüber wissen musst.
Was ist eine robots.txt?
Bei einer robots.txt-Datei handelt es sich um eine einfache Textdatei, die du im Root-Verzeichnis deiner Domain ablegst. Sie enthält Anweisungen in Form von User-Agent- oder Disallow-Direktiven, mit denen du festlegen kannst, welche Inhalte welche Crawler crawlen dürfen und welche nicht. Das hilft, das Crawling‑Budget effizienter zu nutzen und sicherzustellen, dass wichtige Inhalte priorisiert gecrawlt werden.
💡 Mit User-Agent ist der spezifische Crawler gemeint wie beispielsweise der Googlebot oder der Bingbot. Disallow bezeichnet die URLs oder Pfade, die nicht gecrawlt werden dürfen.
Was ist eine XML-Sitemap?
Eine XML‑Sitemap ist ein strukturierter, meist maschinenlesbarer Dateityp, der URLs deiner Webseite enthält. Darüber hinaus kann die Sitemap auch weitere Informationen enthalten wie Änderungsdaten, Priorität oder Änderungsfrequenz. Sie trägt dazu bei, dass Suchmaschinen‑Crawler neue oder isolierte Unterseiten finden und effizienter indexieren können.
👉 Du möchtest mehr über die XML-Sitemap erfahren? Hier findest du einen umfangreichen XML-Sitemap Guide.
Die Verbindung von Sitemap und robots.txt
Auch wenn die XML-Sitemap und die robots.txt-Datei unterschiedliche Aufgabengebiete haben, ergänzen sie sich perfekt:
- Die robots.txt-Datei dient in erster Linie dazu, Suchmaschinen-Crawlern mitzuteilen, welche Inhalte einer Domain gecrawlt werden dürfen und welche nicht.
- Die Sitemap hingegen listet alle wichtigen URLs einer Webseite auf und erleichtert die Indexierung, indem sie auch schwer zugängliche Unterseiten enthält, die sonst von den Crawlern möglicherweise übersehen würden.
Damit Suchmaschinen beide Elemente besser nutzen können, gibt es die Möglichkeit, in der robots.txt direkt auf die Sitemap zu verweisen. Der Eintrag sieht so aus:
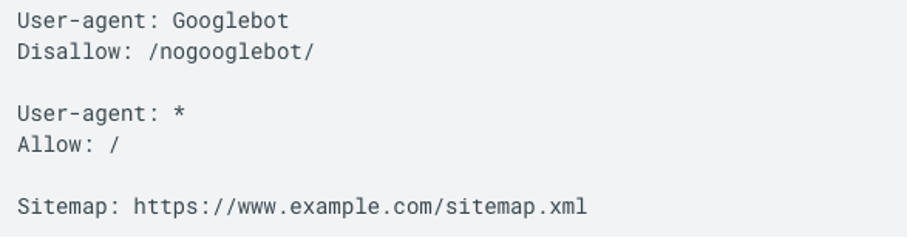
Quelle: https://developers.google.com/search/docs/crawling-indexing/robots/create-robots-txt?hl=de
Dadurch weiß jeder Crawler, der die robots.txt-Datei abruft, sofort, wo er die Sitemap findet. Das spart Zeit beim Crawlen und verbessert die Chance, dass wirklich alle wichtigen Seiten einer Domain schnell indexiert werden.
Best Practices für eine Sitemap in der robots.txt
Beachte bitte folgendes, wenn du eine Sitemap in die robots.txt-Datei integrierst:
- Nur absolute URLs dürfen in der robots.txt verwendet werden. Der Eintrag zur Sitemap muss die vollständige URL beinhalten (wie https://www.deinedomain.de/sitemap.xml).
- Der Eintrag Sitemap: [absoluteURL] kann an beliebiger Stelle in der Datei stehen und wird von Google erkannt.
- Die Anweisung muss korrekt geschrieben und formatiert sein, damit sie ausgelesen werden kann. Google weist darauf hin, dass die Sitemap-Angabe angebracht, aber nicht garantiert verarbeitet wird.
👉 Mehr Infos zu den Best Practices einer robots.txt-Datei findest du im Google Search Central.
Grenzen und Missverständnisse in Bezug auf die robots.txt-Datei
Viele verwechseln robots.txt mit einem „Indexierungsstopp“. Dies ist jedoch nicht richtig. Die robots.txt-Datei verhindert nur das Crawlen, nicht zwingend das Indexieren. Seiten können also trotzdem im Index auftauchen, wenn sie von extern verlinkt sind.
Wenn du sicherstellen möchtest, dass Seiten nicht indexiert werden, solltest du das Meta-Tag „<meta name=“robots“ content=“noindex“>“ oder alternativ den HTTP-Header „X-Robots-Tag: noindex“ verwenden.
Wichtig: Diese Anweisung funktioniert nur, wenn die Seite nicht durch robots.txt blockiert ist, da Googlebot sie sonst nicht auslesen kann.
Fazit
Die robots.txt‑Datei ist sehr wichtig für das Crawler‑Management, denn sie bestimmt, welche Inhalte von Crawlern aufgerufen werden dürfen und welche nicht. Die XML‑Sitemap unterstützt im Gegensatz dazu die Indexierung, indem sie alle relevanten URLs klar auflistet. Besonders effektiv ist die Kombination aus robots.txt und XML-Sitemap: Wenn du in deiner robots.txt deine Sitemap verlinkst, bekommen Suchmaschinen einen klaren Überblick über wichtige Seiten und können effizient gecrawlt und indexiert werden.
FAQ: Sitemap robots.txt
Warum ist die robots.txt-Datei wichtig für SEO?
Die robots.txt Datei ist wichtig, weil sie Crawlern wie von Google zeigt, welche URLs gecrawlt werden dürfen. Dies ist eine wichtige Möglichkeit, das Crawl‑Budget effizient auf wichtige Seiten zu fokussieren und so die SEO‑Performance zu verbessern.
Wie kann ich in der robots.txt-Datei einen Link zu meinen XML-Sitemaps eintragen?
Du musst einfach die Zeile
Sitemap: https://www.deinedomain.de/sitemap.xml
(oder für mehrere Sitemaps entsprechend mehrere Zeilen) in die robots.txt‑Datei einfügen.
Beeinflusst die robots.txt-Datei das Google-Ranking?
Nein, robots.txt ist kein Ranking‑Faktor, sondern steuert nur das Crawler‑Verhalten. Sie kann indirekt das Ranking beeinflussen, indem sie unwichtige Seiten vom Crawling ausschließt und so das Crawl‑Budget auf relevante Inhalte lenkt.

Marco Lauerwald – SEO mit Substanz und Storytelling
Marco Lauerwald steht für strategisches SEO, das Rankings und Marken stärkt. Als Gründer von L17.Digital berät er Unternehmen seit Jahren dabei, ihre digitale Sichtbarkeit datenbasiert und nutzerorientiert aufzubauen.
Hauptberuflich ist Marco Head of Growth bei zvoove, einem führenden Anbieter für Softwarelösungen in der Personaldienstleistung. Dort verantwortet er die digitale Wachstumsstrategie und treibt Marketing-Innovationen aktiv voran.
Quellen
https://developers.google.com/search/docs/crawling-indexing/robots/intro?utm_ (Zugriff 25.08., 09:40 Uhr)
https://digital.gov/resources/introduction-robots-txt-files?utm_ (Zugriff 25.08., 09:53 Uhr)
https://search.gov/indexing/sitemaps.html (Zugriff 25.08., 09:59)
https://developers.google.com/search/docs/crawling-indexing/robots/robots_txt?utm_ (Zugriff 25.08., 15:34)
https://developers.google.com/search/docs/crawling-indexing/sitemaps/build-sitemap?utm_ (Zugriff 25.08., 15:43)
https://developers.google.com/search/docs/crawling-indexing/block-indexing?utm_ (Zugriff 25.08., 15:53)

